












Consolidate & Visualize Energy and Row Material Consumption
Say goodbye to scattered spreadsheets. Get a clear, centralized view of your consumption data and save valuable time.
Discover more >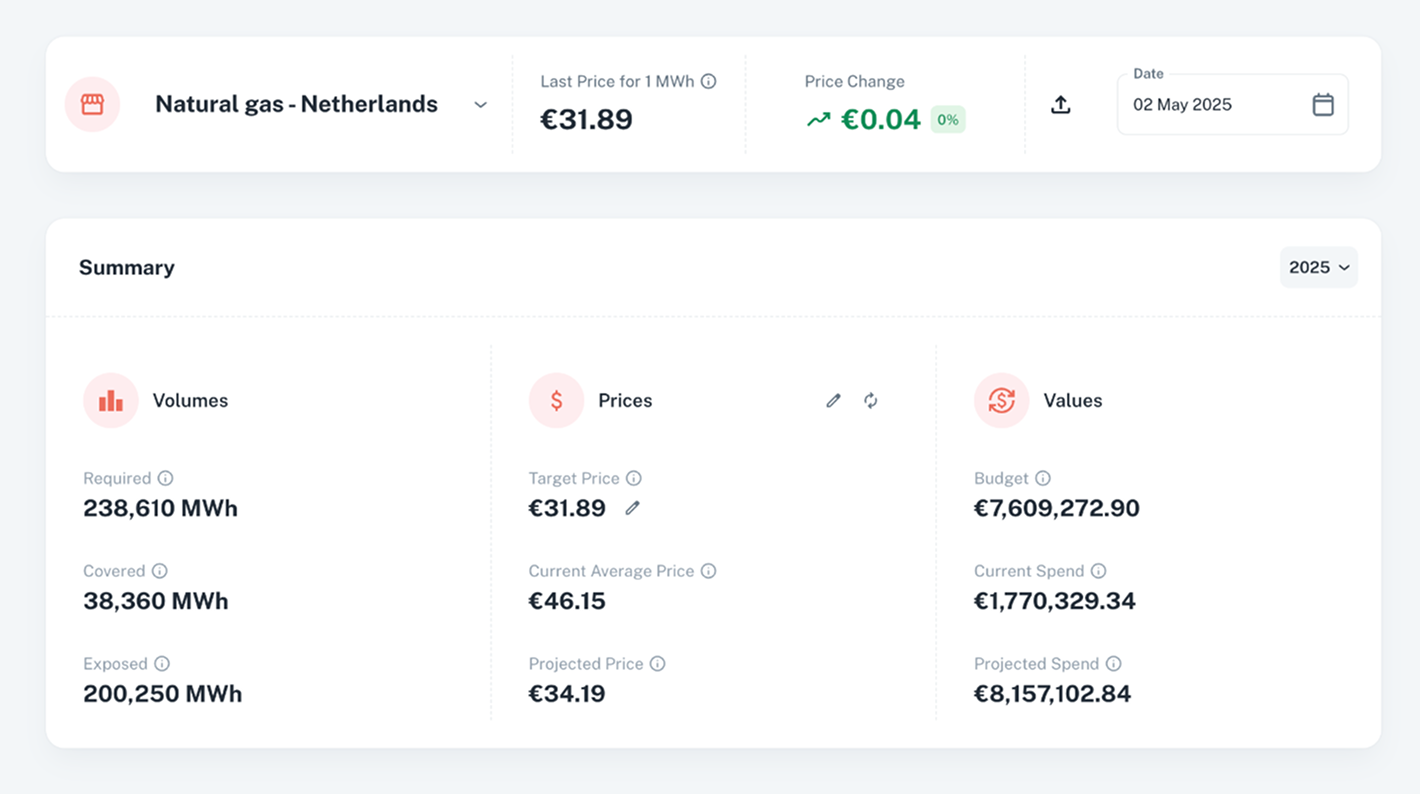
Centralize & Analyze All Historical Transactions
Streamline your processes with one centralized tool delivering instant insights into your procurement past.
Discover more >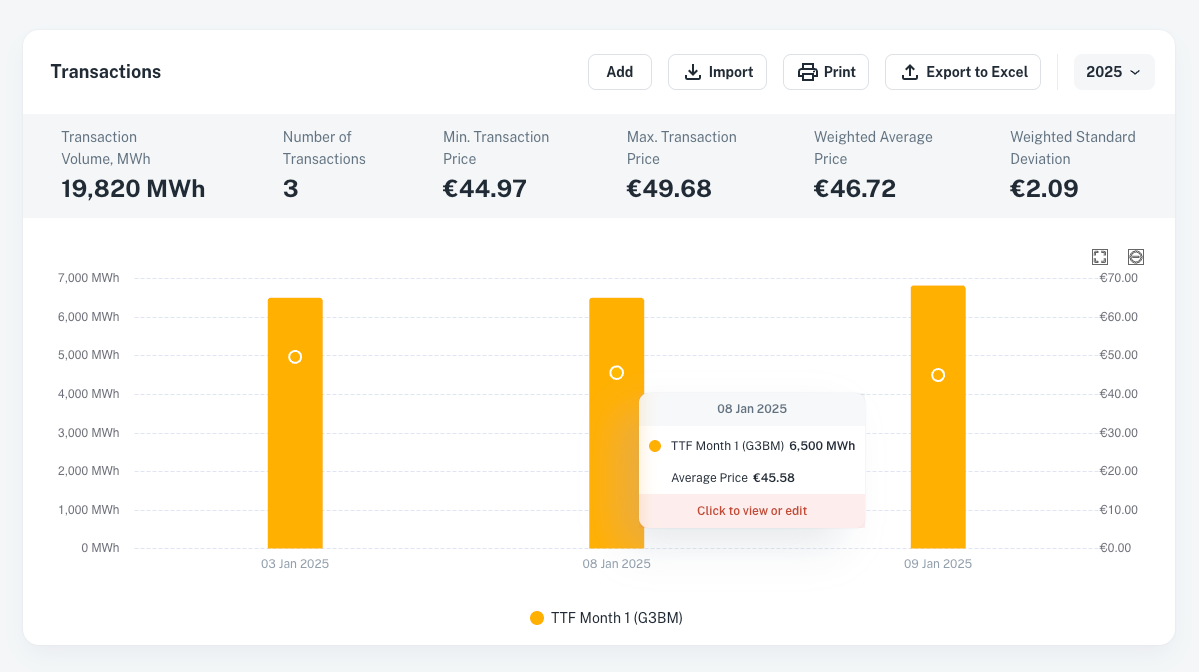
Prices & Volatility : Instant Market Insights
Stay on top of price fluctuations and act with confidence, before volatility impacts your costs.
Discover more >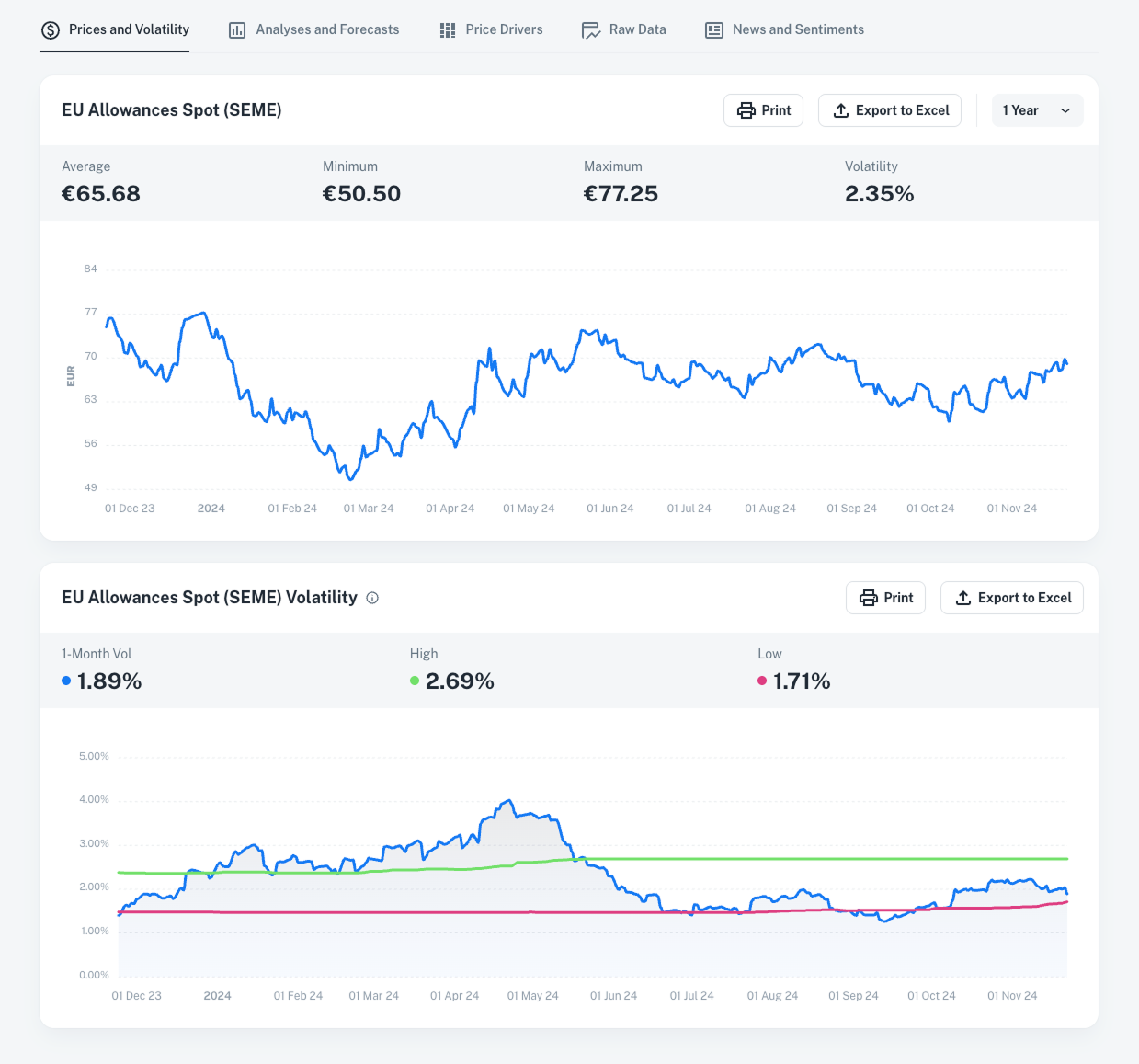
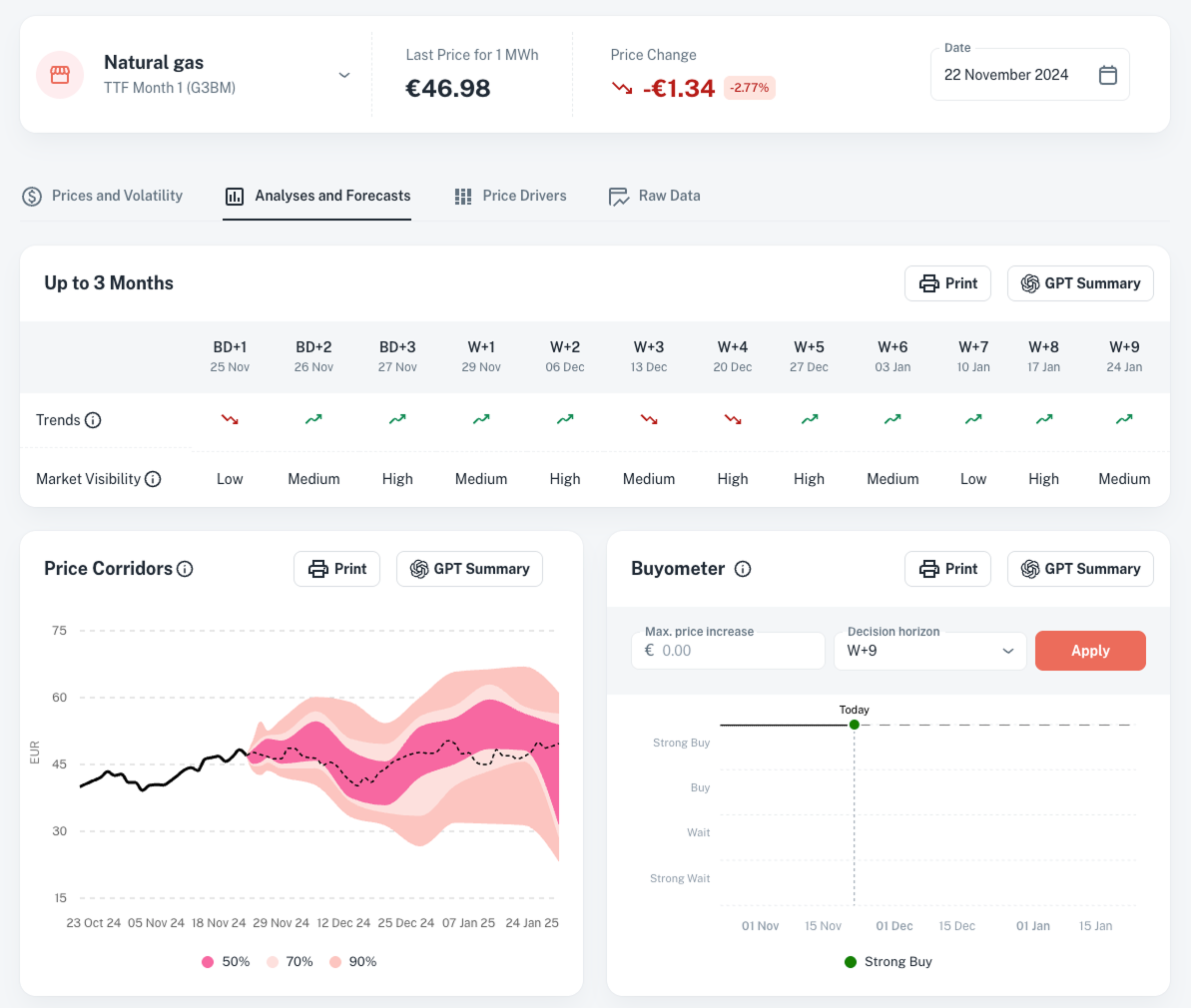
Analyses & Forecasts : AI-Powered Price Projections
Leverage advanced forecasts to align purchasing decisions with future market conditions.
Discover more >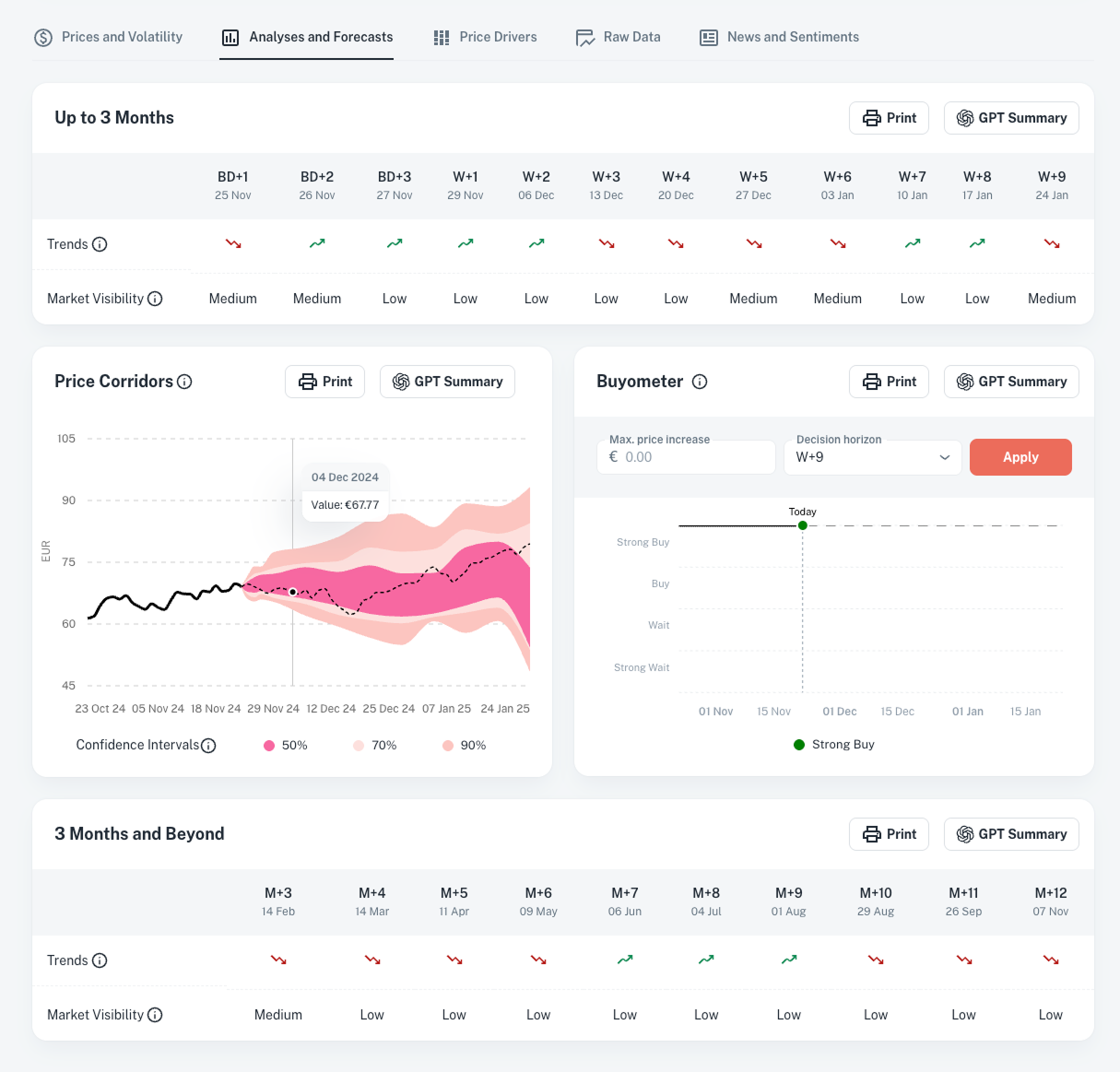
Price Drivers : Understand What Drives Your Market
Identify the variables that matter most to refine your strategy and eliminate data noise.
Discover more >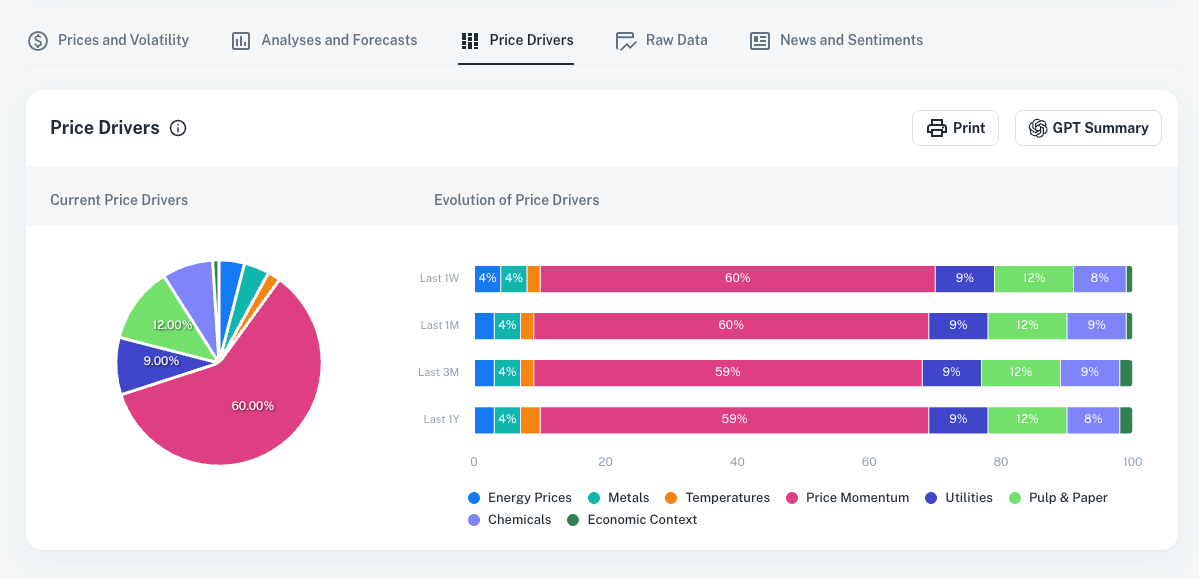
Data Stream Selection : Optimize Your Market Intelligence
Choose only the most relevant data inputs to reduce complexity and control data costs.
Discover more >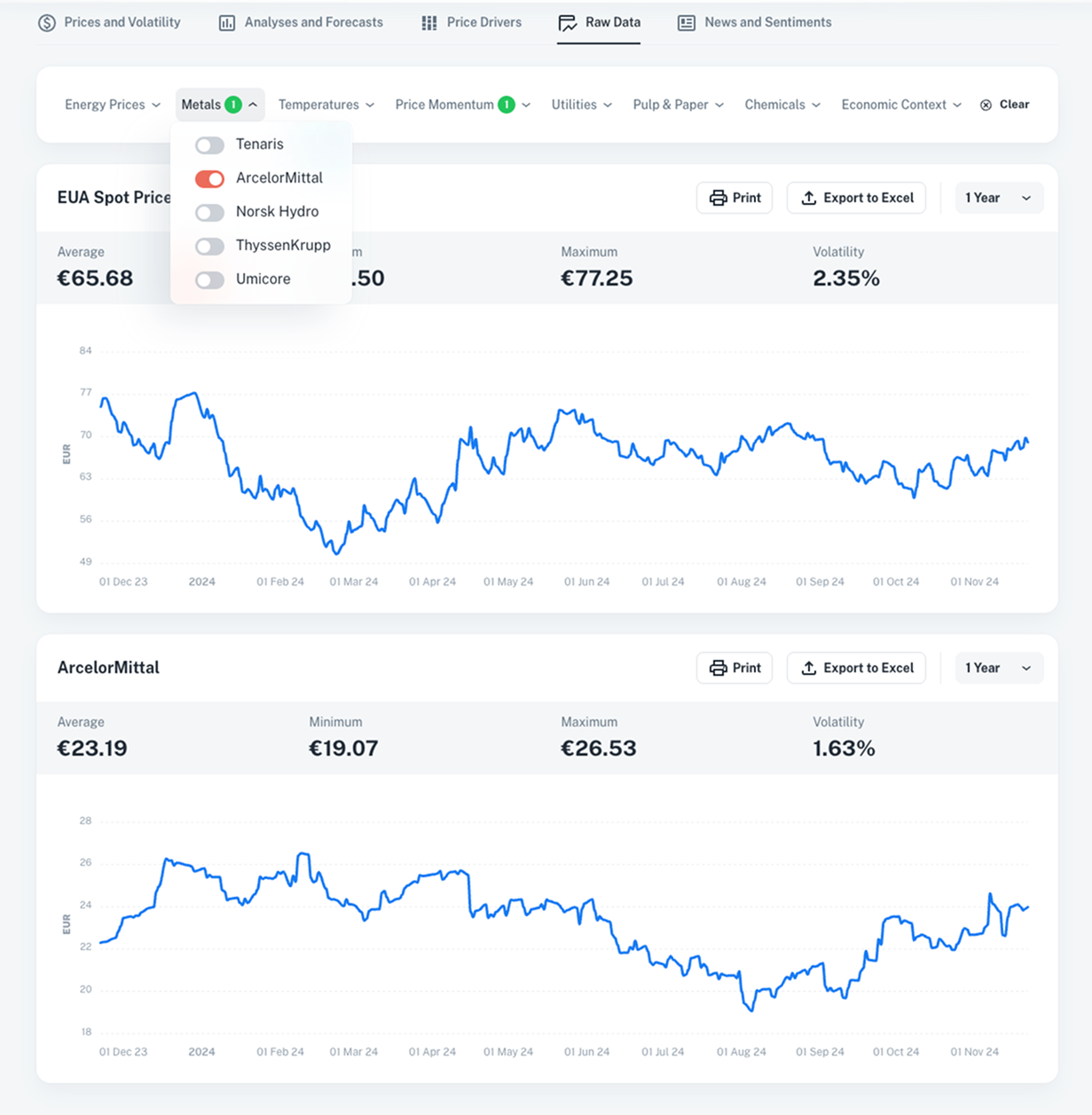
Configuration : Design & Test Multiple Strategies
Explore different purchasing and hedging scenarios in a risk-free environment to find what works best.
Discover more >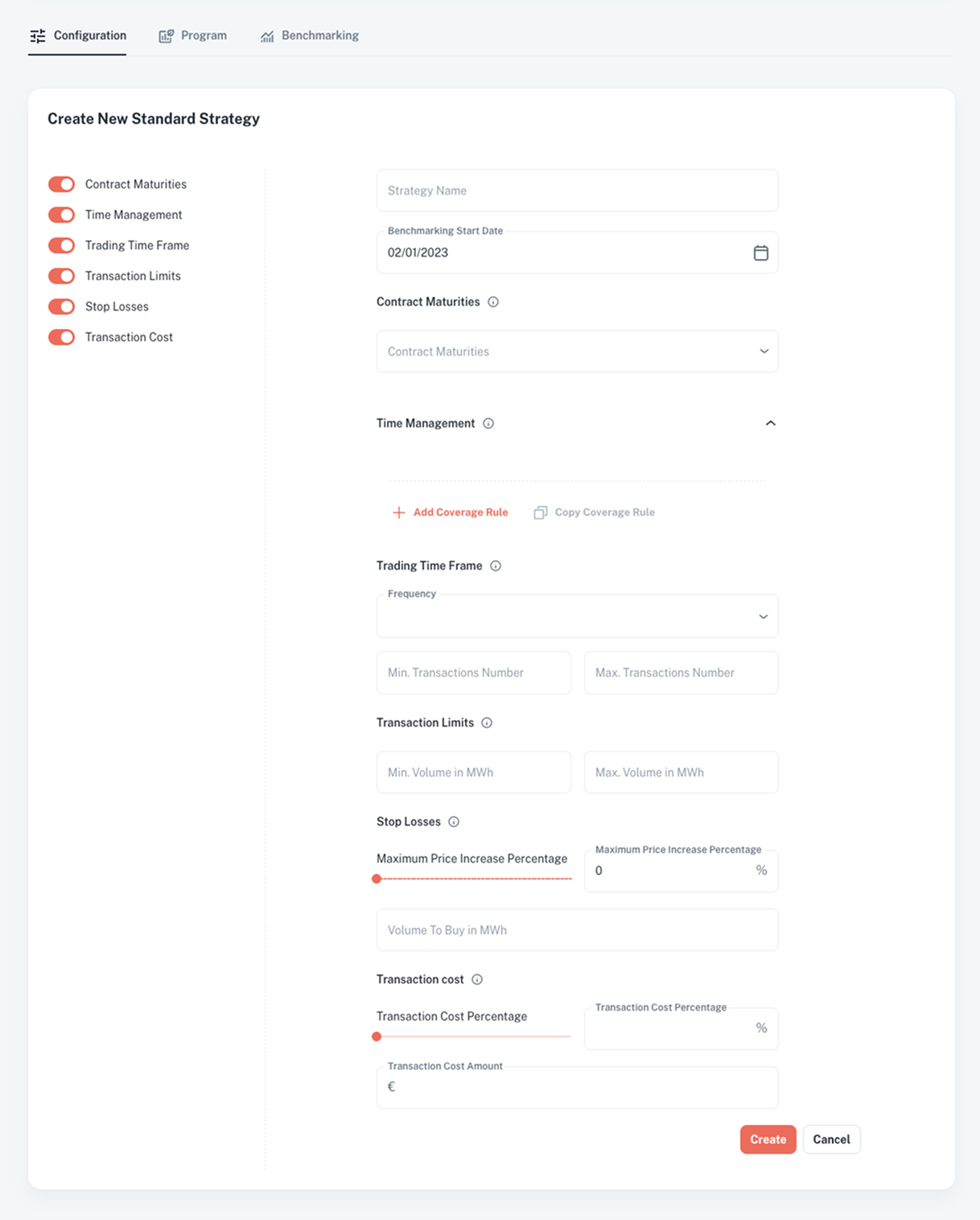
Program : AI-Powered Strategy Execution
Execute AI-enhanced decisions while keeping full ownership, and reduce your procurement costs by up to 5%.
Discover more >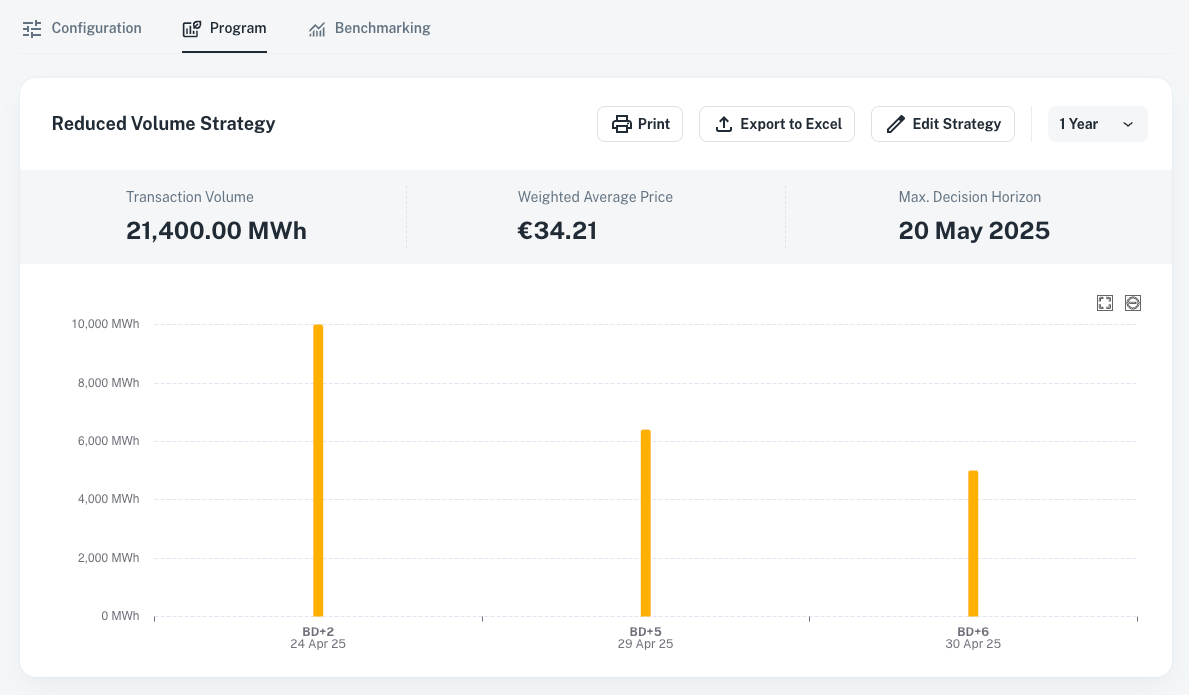
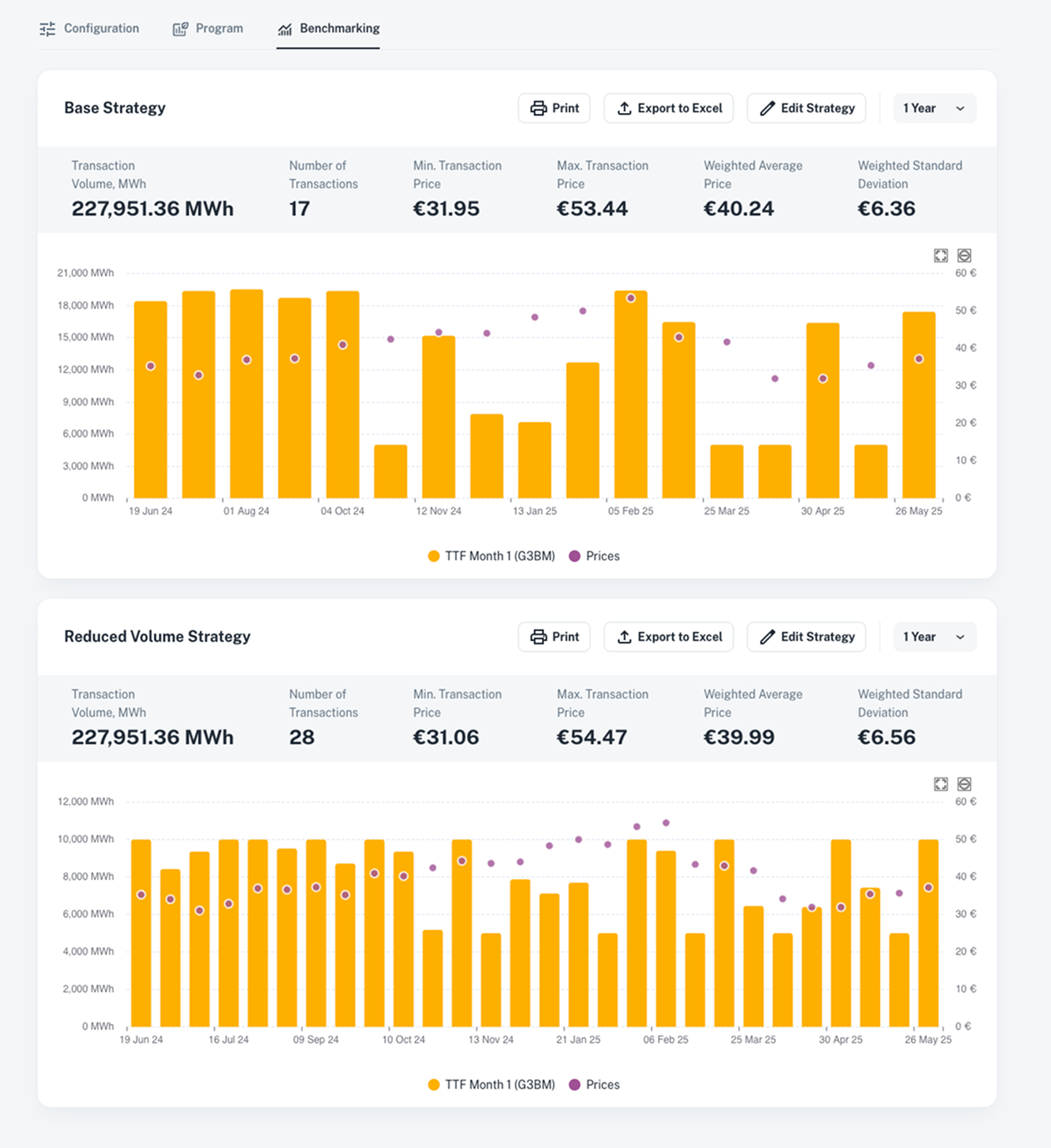
Benchmarking : Compare & Optimize Performance
Compare the impact of your different strategies over time and continuously optimize performance.
Discover more >