
Machine learning models often disappoint in production for a simple reason - they have the wrong target.
Here is a quick example, and a description of our standard solution.
1. The problem
You are the Chief Operations Officer of a manufacturing company, and you want to improve the timing of the purchase orders for your main raw material. Here is the market price for that raw material over the past 12 months:
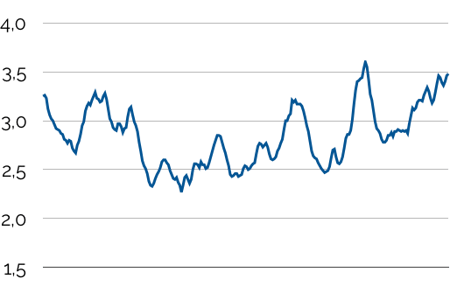
So should you don your « citizen data scientist » hat, jump on your favorite machine learning platform, and minimize an L1 or L2 prediction error for that price?
No so fast.
Because you are operating in real life and not in a data science lab, there is a difference between the price of that raw material on the market and its cost in your factory.
Let us assume some basic constraints to illustrate that point:
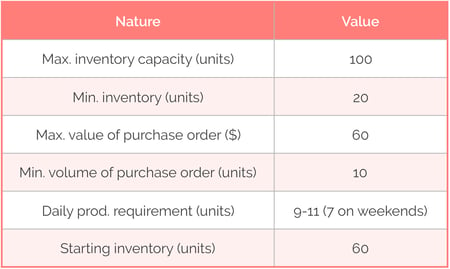
Let us also assume two simple business rules:
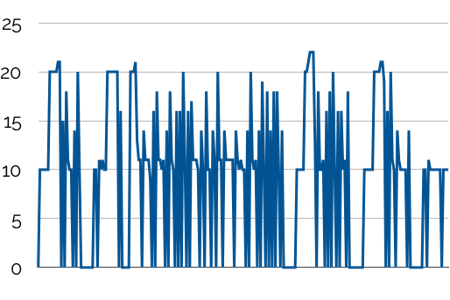
- You buy to the max of your inventory capacity when the market price is below 3. Otherwise, you just replenish to the minimum inventory required.
- You use inventory on a first in, first out basis.
With this, we can generate the schedule of your purchase orders:
And we can calculate the cost of the raw material in your factory:
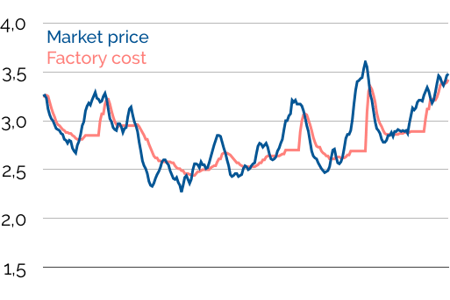
Our simple operational assumptions are enough to generate a discrepancy between market price and factory cost. Greater cost, constraint and business rule complexity would only amplify that (dynamic) difference.
The danger is to be so focused on price prediction accuracy that you forget it is not your real business objective.
2. The solution
The solution is to build an explicit representation of that business objective (the "custom loss function"), then use price predictions to minimize it.
Building the custom loss function
You can’t automate that process. It is really a case of sitting down with domain experts and transposing their explanations into mathematical equations. A few guidelines from our experience:
- Since you are trying to formalize a business objective, it should be expressed in hard currency. Be creative! For example, « minimizing an L1 error for day-ahead price predictions » could become « minimizing my dollar loss when betting on tomorrow’s price trend ». In our raw material example:
Min Loss [Bet Amount (t) x (Price (t+1) - Price (t)) / Price (t)]
- Start simple - you can always add sophistication later on. (By the way, this potential for endless refinement is a big advantage of custom loss functions.)
- Businesses don’t operate in a vacuum. They will always try to minimize their loss function given a set of real-life constraints, that you also need to write down. In our raw material example: 20 < Inventory (t) < 100, 9 < Production (t) < 11 (except weekends), Purchase Order (t) < 60, etc.
Minimizing the custom loss function
The next step - minimizing the loss function under a set of operational constraints - is challenging, and hard to achieve from scratch with open-source machine learning libraries:
- They don’t natively allow the minimization of non-standard classification or prediction errors.
- They don’t include constraint optimization models (not a traditional machine learning task).
Datapred’s standard work-around (built into our modeling engine) is the following:
- Train multiple predictive models by minimizing a standard prediction error. This will give you a portfolio of predictions.
- Convert these predictions into business decisions. This can be straightforward: in the preceding example, raw material purchase orders can result from the binarization (to bet or not to bet) of day-ahead price trend predictions.
- Based on their past performance and using an appropriate aggregation procedure that minimizes the custom loss function, combine these decisions into a single one.
Integrating the operational constraints
You can then feed the combined business decision and the operational contraints you wrote down earlier to an operations research model and get the optimal business decision you were looking for.
***
This process is technically intricate, but (we think) quite intuitive. It will always result in greater operational gains than the mere targeting of a standard prediction error. It is applicable to any situation where combining predictions and constraint optimization makes sense.
***
Datapred's Continuous Intelligence engine let you build and optimize custom loss functions reflecting your true business objectives. Contact us for a discussion of these capabilities.
You can also check this page for a quick guide to Continuous Intelligence and links to interesting third-party resources on that topic.
