In a previous post, we explained the concept of cross-validation for time series, aka backtesting, and why proper backtests matter for time series modeling.
The goal here is to dig deeper and discuss a few coding tips that will help you cross-validate your predictive models correctly.
Introduction - The problem of future leakage
The key to efficient time series modeling is not model sophistication, but avoiding "future leakage": information that should be on the right side of the (moving) train/test partition, but that is leaking to the left side - thus corrupting model performance.
The problem is that future leakage, while easy to understand, is often hard to detect. For example, can you spot it in the following ten lines of code?
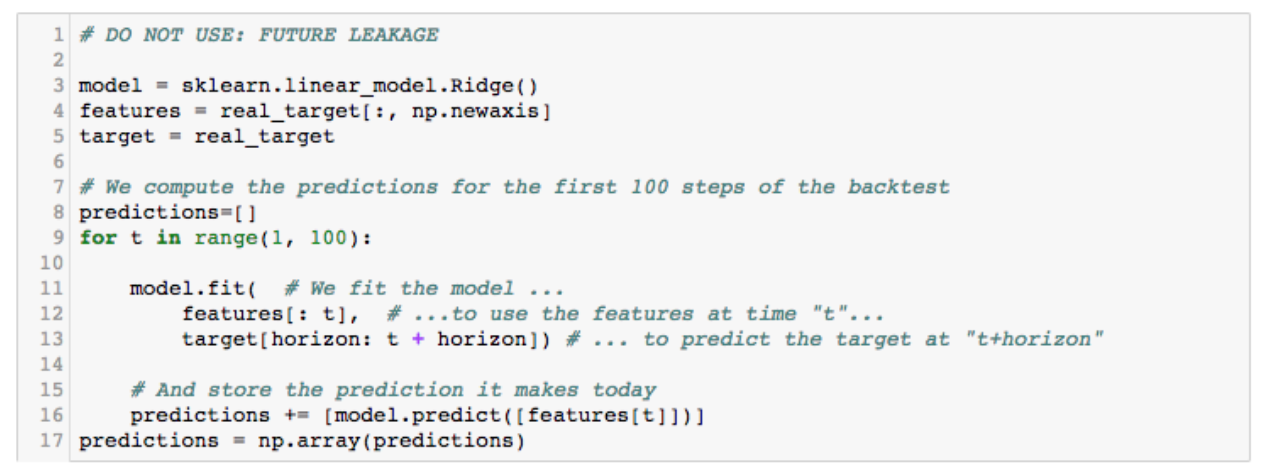
- Line 4: We are using the target as a feature for this ridge regression - so far so good.
- Line 13: When training the model, we are only using the past to predict the future - also correct.
- Line 13: The training data contains samples from the future, i.e. not available at time t (cf. target[horizon: t + horizon]). Bad!
First life saver - Training window management
The first priority to avoid future leakage is to make sure your model stops training as soon as it catches up with the prediction target.
Here is the correct code for the previous example:

You can see in the "for" loop (starting line 7) that we never use an index greater than t - meaning that we only use past data for model training.
That is quite simple in principle, but remembering and coding it every time you build a machine learning solution for time series is cumbersome and risky. It is much better to automate it, if you can.
Second life saver - Feature shifting
Managing the prediction target correctly is not enough - you also need to handle your features correctly. With time series, this often involves lots of data shifting along the time axis.
The reason is that some features, while technically in the past, may include information about the future. For example a marketing plan disclosed last month may specify the company's marketing spend for the next 12 months. In that case:
- The feature "marketing plan", while time-stamped at t - 30, actually informs us today about the next 12 months.
- So you want to shift that feature to today, and use it to predict the next few months.
Such shifts complexify training window management considerably, thus increasing the danger of future leakage.
Coding them from scratch with Python or R is challenging, especially with multiple project contributors and/or for solutions that require hyper-parameter optimization. Ideally, you want to automate and recycle the shifts as much as possible.
If you can't do that, the next section may save your life :)
Third life saver - The zero test
Knowing how to avoid future leakage is great, but how can you quickly check that your code is safe?
For that, we use a simple and effective technique that we call the “zero test”. It consists in running your model twice: once with the regular target, and once where target values following a certain date are set to zero:
- artificial_target = real_target.copy()
- artificial_target[zero_date:] *= 0
The predictions of the resulting machine learning pipelines should be identical up to zero_date + [prediction horizon], and differ after that. If they start differing before that date, congratulations - you have detected future leakage.
For example, here is the zero test applied to the incorrect code of our introductory example (with zero_date = 80 and prediction horizon = 14):
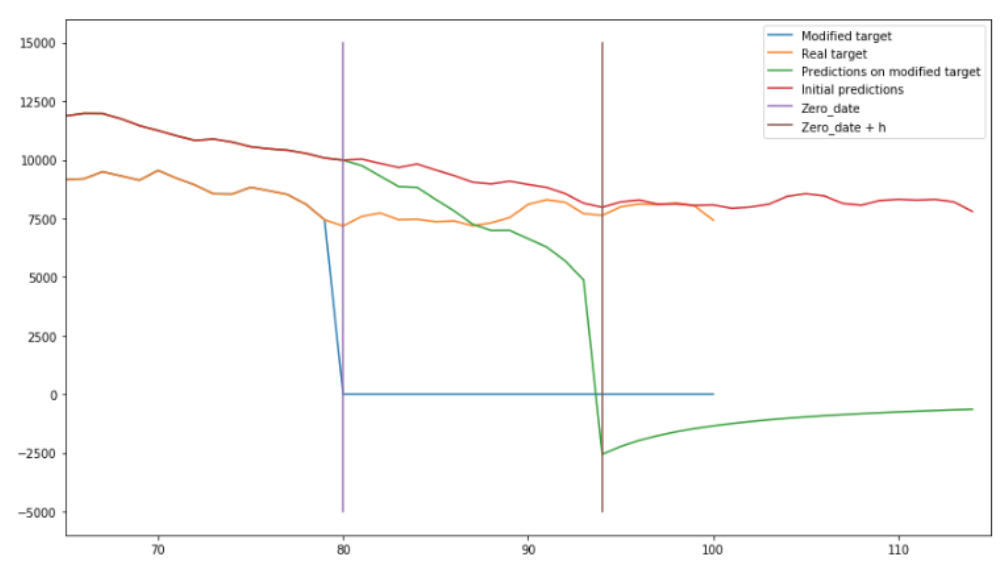
The blue line, suddenly dropping to zero at t = 80, is our modified target. The green line plots our predictions for that modified target, and its diverging from the red line (plotting our predictions for the original target) after t = 80 reveals that we are suffering from feature leakage (without feature leakage, the green and red line would have diverged after t = 94).
***
Datapred automates training window management, feature shifting and the zero test... Don't hesitate to contact us for a discussion of these capabilities! And for additional information on all aspects of time series modeling, this page is a good starting point.
