
Time series modeling requires the understanding of concepts that feel both basic and abstract:
- Only the future is truly unknown
- Data transitions directly from future to past
- Time is unidirectional
- The future lasts a long time
Points 2 and 3 explain why sequentiality alone defines time series - not nature (quantitative/qualitative, internal/contextual, flat/hierarchical), frequency or regularity.
Points 1, 2 and 3 explain why randomly selecting training, validation and testing sets in your data doesn’t work for time series. It doesn't reflect the sequential discovery process of time series and creates a huge risk of« future leakage ».
Points 1 and 3 explain why prediction accuracy is the only true measure of performance for time series modeling, whether you are explicitly working on a prediction challenge, or on clustering, simulation, anomaly detection…
Points 1, 2 and 4 explain why « waiting a while to confirm model performance » doesn’t make sense. You could wait forever and still find yourself where you are today: measured performance is past, and future performance is uncertain.
The only way to get out of this conundrum is by using a training and testing procedure called backtesting.
Backtesting is used extensively in quantitative finance, but is surprisingly uncommon in machine learning.
The idea is simple: at every moment in your data set, train your model on known/past data at that moment, and test it on unknown/future data at that moment.
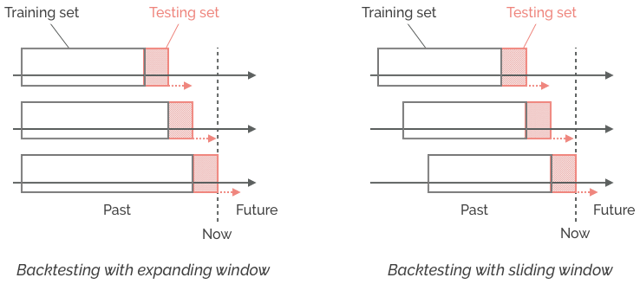
Notable aspects of backtesting:
- It is natively sequential and as close to real-life conditions as possible. With the proviso of point 1 above, solid backtests provide the best assurance you can get on your model's future performance.
- « Waiting a while to confirm model performance » is just a protracted way to backtest the model - no different in nature from (and not safer than) the backtests you could perform today.
- Backtests don't use validation sets, since every data point is already (and consecutively) part of the testing and training sets. Classic cross-validation is neither required nor recommended, because hyper-parameter selection is performed sequentially.
- You can freely adjust the size and behavior of your training and testing sets based on the specificities of your modeling challenge - provided you respect the rigid separation between past and future data at every moment of the backtest.
- Backtests accommodate any performance measure, from standard prediction errors to complex cost functions. This is very useful for targeting your actual industrial objective directly - for example, maximizing/minimizing the dollar gains/losses resulting from good/bad inventory predictions, instead of minimizing an inventory prediction error.
Of course, not everything in the backtesting garden is rosy. Things can become quite thorny when you start juggling with input frequencies, training and testing intervals, prediction horizons...
We discuss advanced aspects of backtesting in an another article. You can also check this page for a list of resources on machine learning for time series, and contact us to learn how Datapred automates backtesting.
