
Data scientists are waking up to the fact that combining multiple, relatively simple predictive models is often more efficient, when tackling a time series forecasting challenge, than using the latest super-duper neural network.
One question remains - how should you combine these models?
Stacking is the popular answer. It is not the best one...
The problems with stacking
Stacking is a supervised ensemble learning technique. The idea is to combine base predictive models into a higher-level model with lower bias and variance. So far so good, but...
Stacking assumes that data is IID
Stacking makes the standard machine learning assumption that data is independent and identically distributed ("IID").
While that suits lots of data, it rarely applies to real-life time series:
- Real-life phenomenons (physical or business) tend to be time-dependent. If sales are soaring today, they will likely increase tomorrow; if a rotor start vibrating now, it will likely vibrate in 5 seconds...
- They are rarely identically distributed, but are subject to significant statistical regime changes - from low to high volatility for example.
As a consequence, stacking will be good at replicating seasonal patterns, but will fail when facing truly non-stationary time series.
Stacking is computationally intensive
The way stacking combines base models is a bit cumbersome:
- Base models generate their predictions.
- The higher-level model (typically a Random Forest or a logistic regression) uses these predictions as inputs, and returns synthetic, hopefully improved predictions.
That's a lot of calculations - especially when using multiple layers of stacked models, since stacking works by batches: updating the higher-level model requires re-training everything on the entire dataset.
Stacking lacks interpretability
It is easy to understand that increasing the modeling distance between inputs and outputs reduces interpretability. This well-known problem with deep learning also affects stacking: after x layers of stacked Random Forests, finding the contribution of a given input to final prediction accuracy becomes a full-time job.
And addressing that problem with a model-agnostic interpretation method such as LIME involves more parameter tuning, thus complicating the productization of the solution.
Sequential aggregation - The smart alternative for time series
Sequential aggregation is...
- Sequential: models are trained and tested incrementally, every time new data appears, without assuming that data is IID.
- The combination of multiple predictive models: all of them used at the same time, without limitation to the number and nature of these models.
The key difference with stacking is that base models are combined linearly, not via additional layers of models.
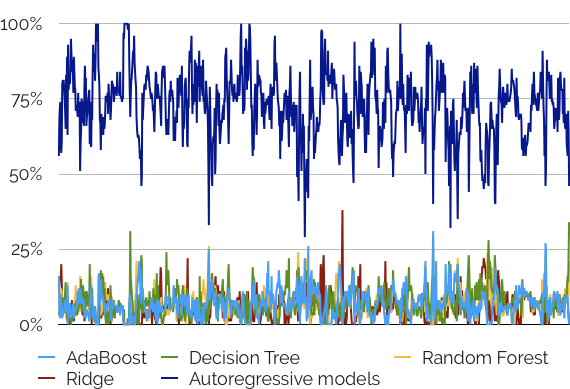
Base models receive positive weights summing to one, and updating incrementally based on their performance. The following graph is an example of model weights changing over time (on an oil price prediction challenge):
Significant benefits
This combination mechanism has two interesting direct consequences.
- Computational efficiency: sequential aggregation procedures are very effective computationally. Updating results at t+1 only requires base model weights at t, the new t+1 data, and the (usually light weight) update formula.
- Interpretability: understanding the contribution of each model to the overall performance of the aggregation is immediate. If interpretability is important for your modeling project, you can even leverage the flexibility of the aggregation procedure to group inputs into meaningful subsets, and/or dedicate some models to specific inputs/inputs subsets. Visualizing aggregation weights will then tell you which inputs contribute at any given time.
Another, less obvious advantage is that sequential aggregation accommodates non-standard prediction errors (in addition to classic classification and regression errors), as long as they are convex. And as we discussed in a previous article, this is key to avoiding production disappointments and transforming nerdy machine learning applications into business-oriented decision management solutions.
***
Datapred automates both stacking and sequential aggregation. Feel free to contact us for a discussion these capabilities in the context of your modeling projects. And for additional resources on time series modeling, this page is a good place to start.
